
Developing Resell Monster
Developer Note: The source code for this software is now public! GitHub

Well, let's begin…
Resell Monster is an older software of mine that I worked on from my junior year of high school to my freshman year of college that basically automatically purchased limited “hype” products online. It all started with my friend introducing me to the profitability of flipping limited release sneakers by buying them when they first come out and reselling them later for an average of 50-100% profit. He was in all sorts of online groups that told him which sneakers to buy, when, and how. We were so interested in this idea that we decided to launch our own group ourselves and spread positivity and information to the community. This group in this space is called a “cook group.” After launching our own group called Kuri Notify, we quickly gained a following of a couple of hundred members and decided to take things to the next level.
It quickly began apparent that in order to buy these sneakers at the retail price, we would have to use a bot because they quickly take the majority of the newly released sneakers' stock within minutes or sometimes seconds. This piqued my interest as a software developer, so I began some research as to how these bots actually worked. I soon realized that I wanted to make my own.
The process of making a bot quickly seemed to be a large task, so I had to break it down into our first stage: figuring out how to scrape the products efficiently and quickly from a website. This stage influenced the overall design of our software. We began to provide software that monitored over two hundred of the most common limited hype sneaker release sites and notified our members as soon as possible, which quickly became a passion of mine to work on after school until late at night, most nights. I've easily spent a couple of hundred hours refining this process and quickly became my specialty in the area.
At this point, our software was called Resell Companion and had over 3,500 users signed up for our community Discord server, a couple of thousand downloads on our software, and upwards of a hundred live users daily. At this stage, we sold our software to select individuals for $15 monthly and offered a free trial to the majority of our userbase. Its main functionality was our "monitors" tab, which had high-speed monitors for 200+ Shopify-based stores, Supreme stores in several regions, SNKRS in several regions, Adidas, and more. We stuck out because we not only offered this single feature but because of the numerous other features we offered. Another popular feature we provided was our "browsers" feature which allowed our users to open as many anonymous and uniquely identifying browsers as they would like to enter infinite queues for queue-based releases for Adidas and Yeezy Supply. I personally used this feature to anonymously stream about twenty streams of the game Valorant on Twitch at once when the game first came out to generate private access beta keys, for which I sold for a premium shortly after for a couple of hundred bucks.
With this, our community was head over heels for our software. I then decided to implement high-speed social media monitors (we called Social+) for Twitter and Instagram for exclusive niche releases or really for whatever our users wanted to use them for. This feature grew our success immensely and definitely was one of the major reasons why so many people loved our software.
After practically mastering highly efficient web-scraping (the process described below), I decided to expand our program to actually automatically check out. This process was difficult but because of my experience taking apart these websites to scrape their products, I managed to actually figure it out. I had to launch checkout sessions and whenever prompted for a captcha, the software would display a separate captcha in a simple managed window to the user and have them fill out the captcha. After, the resultant captcha key would be imported into the checkout session and we would finalize the checkout. Of course, some websites like Supreme implemented higher-security measures to prevent this but were easily avoidable if the checkout sessions were hosted in a separate Chromium window by injecting an appropriate preload script (this script essentially masked our identity by falsifying browser features and plug-ins).
The process of making a fully-featured all-in-one (AIO) bot
Product Scraping
At first, I began writing my monitors using Python because of its simplicity and the vast amount of tutorials for web scraping online but because of its slow speed, I had to switch to another programming language. I experimented with Node.js at this time because of my familiarity with JavaScript and the monitors worked pretty well for several months but after lots of research and trial/error, I realized that although web scraping with Node.js is really simple and decently efficient, I wanted to be the best in the area so I switched to Golang. This language is highly efficient for web scraping and has processing speeds comparable to C++, so this is the language I chose to write the final product scraping monitors in.
To begin web scraping, it is firstly important to understand the security measures a website has. The security breakdown for scraping/botting these limited hype sneaker release stores was as follows (at least at the time):
-
Shopify-based websites: Some stores may require a captcha at most (easiest to monitor / bot)
-
SNKRS: Akamai security (uses fingerprinting and cookies to detect bots - to bypass we need to generate cookies for akamai before scraping the website. This can be done intermittently throughout the day to have consistent web scraping). If SNKRS detects the request as a bot, it may either give delayed data (that is unuseful to us because the sneaker will already be sold out) or no data at all.
-
Supreme: Pooky.js Anti Bot Detection (only enabled on Thursdays at 11 am EST whenever there is a new release, uses cookie generation to checkout rather than sending requests to Supreme... if you try to checkout without the generated pooky cookie, then you will be declined)
-
Off-White: Variti Active Bot Protection (uses fingerprinting - to bypass we need a good cipher / user-agent combination)
-
Footsites (Footlocker, Footaction, Eastbay, Champs, etc): Datadome Bot Protection (uses fingerprinting - to bypass we need simple chromedriver manipulation)
-
Mesh (Hipstore, JD Sports, Foot Patrol, etc): Simple fingerprinting and requires powerful residential proxies.
After creating these high-speed monitors, I had to come up with a solution to display the scraped products to the users almost instantaneously to maintain their speed, so I decided on using WebSockets. At first, I paid for Pusher, an easy-to-use WebSocket API, but their costs were rather high and did not offer a plan that made sense to us so instead, I wrote my own WebSocket API that only costed about $5 a month (hosted on a base DigitalOcean droplet) and allowed for maximum speed with no limits on the number of concurrent connections or messages sent. This WebSocket connected directly to both my software and also formatted itself to display live updates about products in our community Discord.
Here's what our Monitors feature looked like in our software (the UI below is in Spanish since we offered up to 11 different languages):
.12b5d40d.png&w=3840&q=75)
Proxies
For all web scraping besides Shopify, we had to use expensive rotating residential proxies. Residential proxies are basically proxies that are not hosted on a large data server but instead disguise the connection as if it were coming from a normal residential house. Where you buy these proxies matters a lot to avoid blacklisted IPs from major proxy companies, so we found and partnered with the small business Blazing SEO. We advertised their services for a discount on their prices (20% lifetime discount) for their proxies and ended up costing us on average ~$75 a month. This cost was covered by our select monthly recurring user payments though so upkeep for the software was kept at a minimum and we actually profited each month in which we reinvested into digital art and marketing. Since we automatically monitored these sites with our own proxies, our userbase did not have to spend much on proxies besides for checking out since that is done locally on their machine.
reCAPTCHA Solving
Whenever a Google reCAPTCHA appeared at the checkout of a product, a new reCAPTCHA window would appear (view below) and my software would automatically load the website to an invalid 404 page (for minimal DOM element rendering for efficiency), clear the page contents, and inject a new reCAPTCHA to one of the Captcha Solver windows with the correct site key (this is what reCAPTCHA uses to identify/verify the reCAPTCHA correlates with the correct current website host). I would then inject a script that would await for Google's sendCaptcha method to be called (this is the immediate method Google's reCAPTCHA calls upon a successful reCAPTCHA completion), and rather than sending the response, it would redirect the reCAPTCHA response to the already opened checkout window. This method also allows users to fill out reCAPTCHA for the website up to two minutes prior to the release so our users could have instantaneous reCAPTCHA solving for their checkouts, maximizing speed and efficiency.

Google's reCAPTCHAs store the response to the reCAPTCHA in a <textarea> directly underneath the reCAPTCHA as soon as it's solved. This is the response code that we redirect to the checkout. Here's what it would look like if we were to unhide the <textarea>:
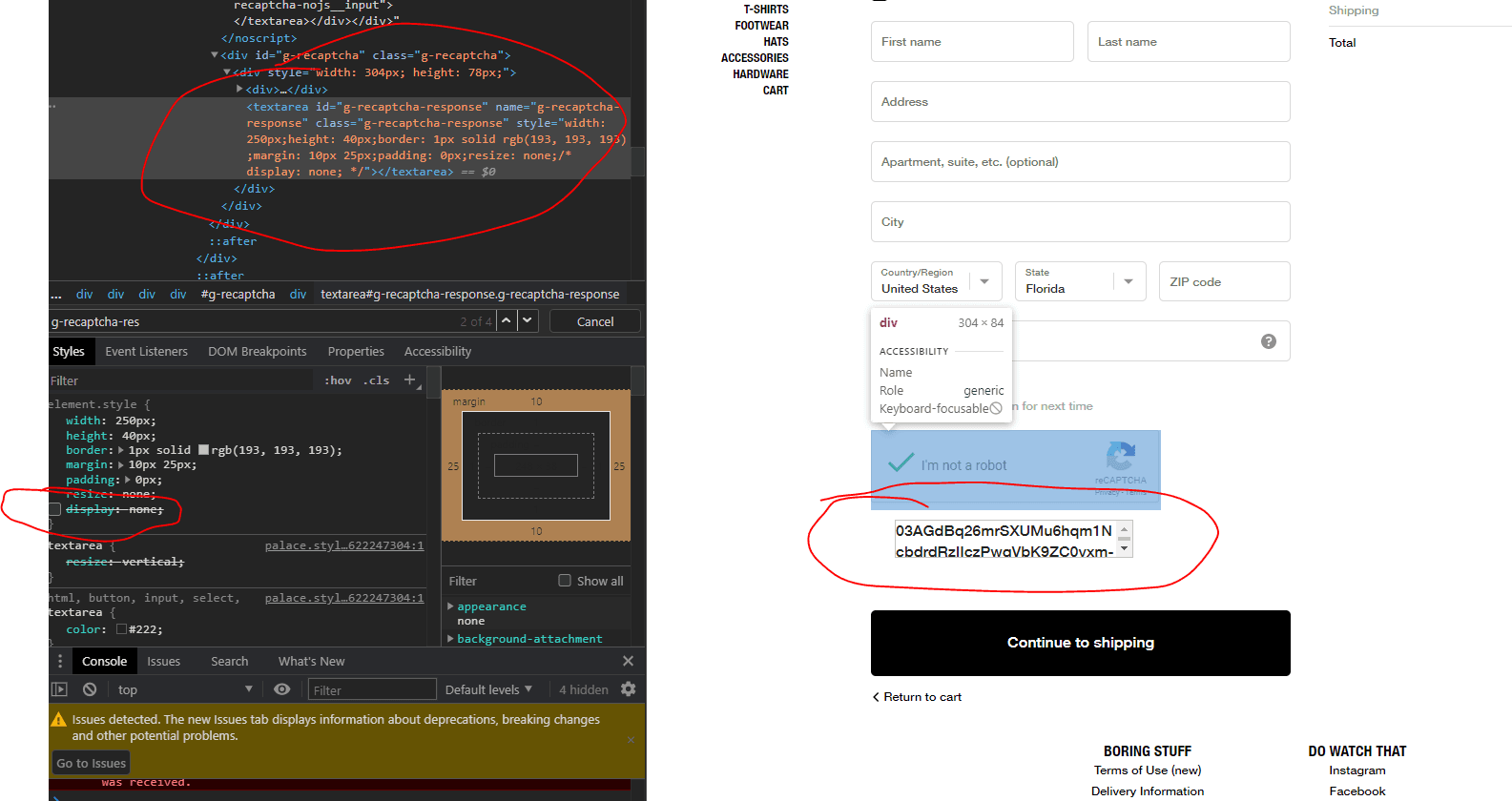
Location Spoofing
One of our initial features is this location spoofing feature which would put any iOS device (iPad, iPhone, iPod, etc) to any location that the user selected. This is especially useful for location-specific releases which were hosted on an app from the App Store like SNKRS.
The process of writing this feature was actually pretty difficult. Since I wrote Resell Companion using Node.js, communicating with an iOS device is not an easy task, so I decided to write an external software that worked in the background alongside the Node.js application in C#. I decided upon using C# because I found a library written in C that communicates with iOS devices natively called iMobileDevice. The one problem I initially ran into was that as new releases of iOS came out, the Spoof feature would stop working because iMobileDevice requires the most up-to-date Developer Disk Image to communicate with the device, so I found a repository on GitHub that constantly uploaded new Developer Disk Images as soon as the new versions of iOS come out. This was key to making the Spoof software work, and then it consistently did.
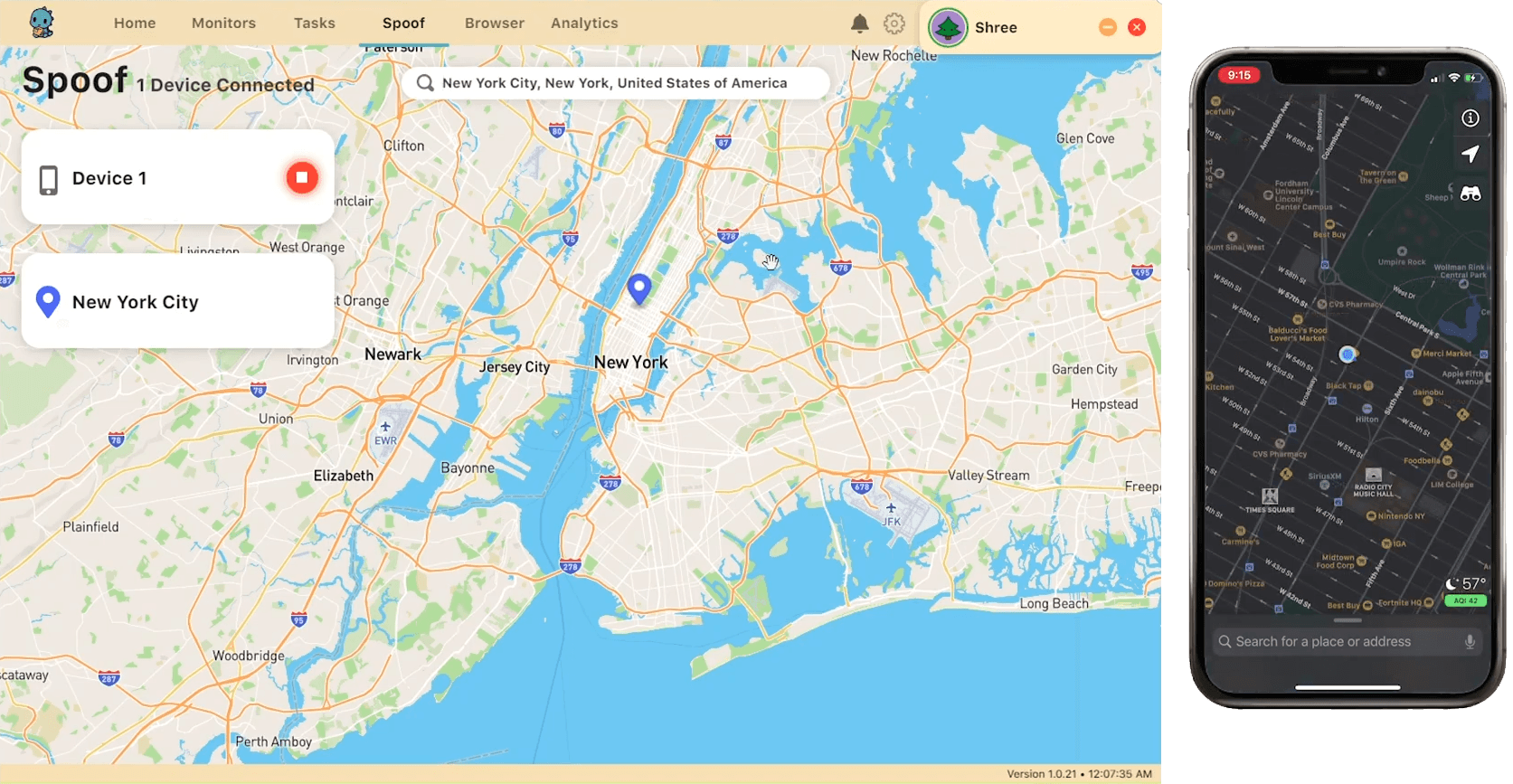
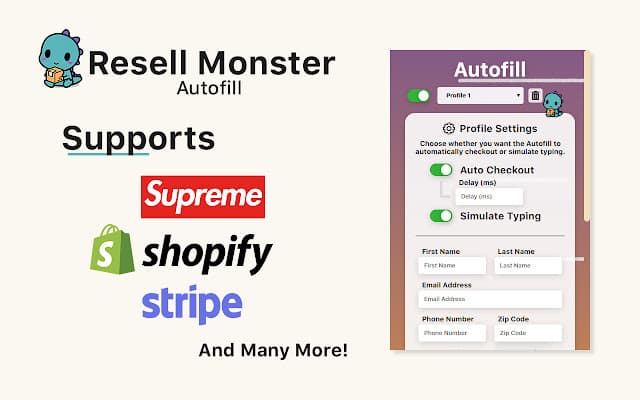
Custom Google Chrome Extension
For some releases, it is actually more reliable to use Google Chrome alongside our bot to guarantee at least a single checkout. This was my preferred approach for Shopify-based/Supreme releases because of the occasional last-minute anti-bot features that would be sometimes implemented moments before a release. I wrote the extension in JavaScript and used Adobe XD to prototype the extension's interface.
The extension included automatic checkouts (with custom optional delay after automatically inputting the autofill information) and had a feature to simulate typing to prevent stores from detecting the use of an autofill on their site. I also decided to allow our users to have multiple profiles set up in case they want to attempt several checkouts with varying information.
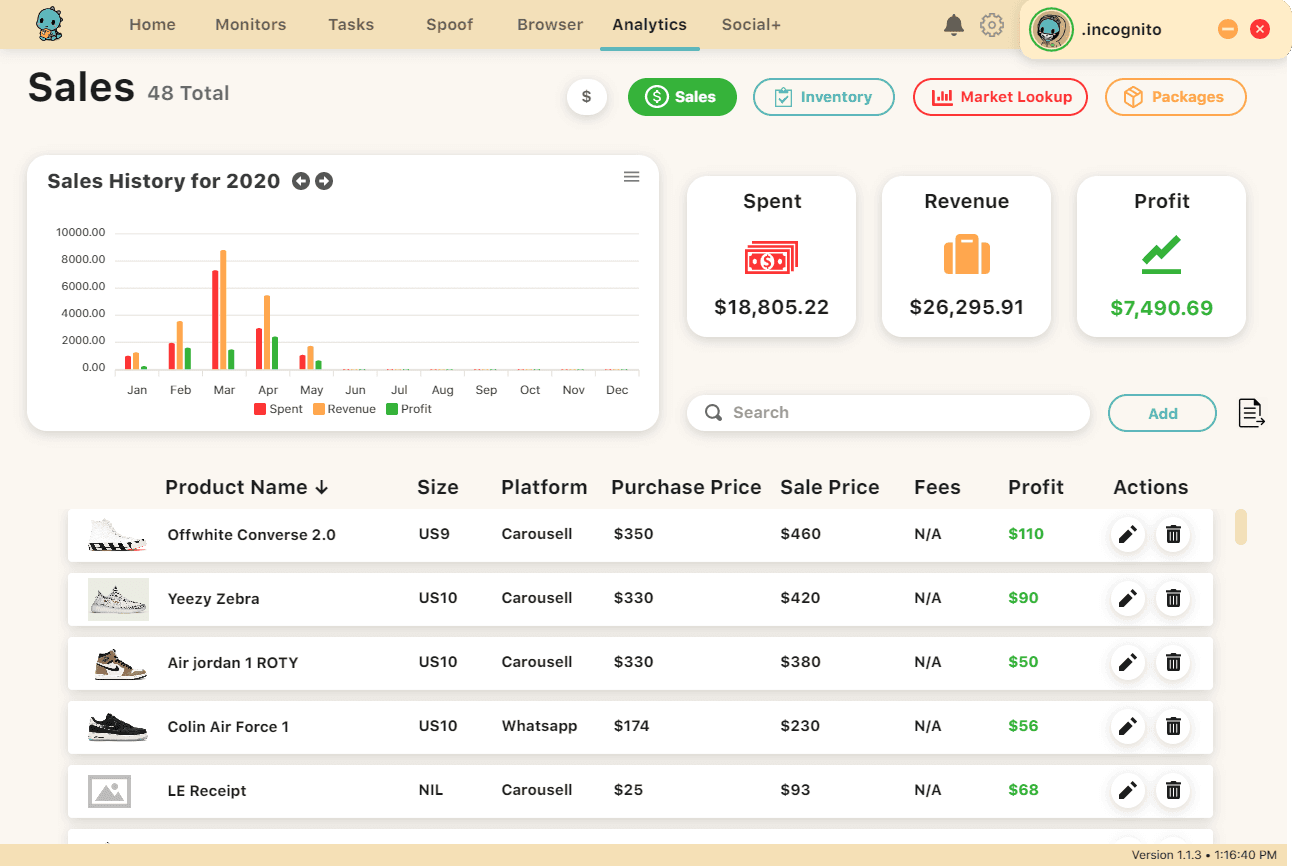
Analytics
We stored our users' analytics on the cloud so they would always have access to their information no matter which computer they used. It kept track of their sales, automatically added successful checkouts to their inventory, and had a market lookup feature to compare products in their inventory to prices on GOAT, StockX, and other similar marketplaces. Another feature in our analytics is automatic package tracking, where we would notify our users about shipping updates on their newly purchases sneakers.
Here's a screenshot of what the Analytics feature looked like on the first update of the software:
Where we are today
Although the success of our software and its potential, my friend that I joined this venture with shifted his passions and we split our separate way once we went out to college. The software today has not been worked on since August 2020.